我院刘怡俊教授团队在集成电路与超大规模系统领域国际顶级期刊《IEEE Transactions on Very Large Scale Integration Systems》(T-VLSI)上发表了题为《SConvNSys: Accelerating Spiking Convolutional Neural Networks With a Reconfigurable Neuromorphic Architecture for Diverse Applications》的研究论文。

随着脉冲神经网络(SNN)在视觉识别、图像分割和目标检测等复杂智能任务中不断取得突破,其整体性能已逐步接近甚至达到传统卷积神经网络的水平。如何以低功耗方式实现多样结构SNN模型的高效计算,成为推动其实际应用的关键技术挑战。然而,现有多数SNN加速器难以适配多种卷积类型和不同网络拓扑,导致模型性能无法充分发挥,限制了其在边缘智能等资源受限场景中的落地。针对这一挑战,团队提出一种新型可重构神经形态架构SConvNSys,旨在高效加速面向多类应用场景的脉冲卷积神经网络(SCNN)。
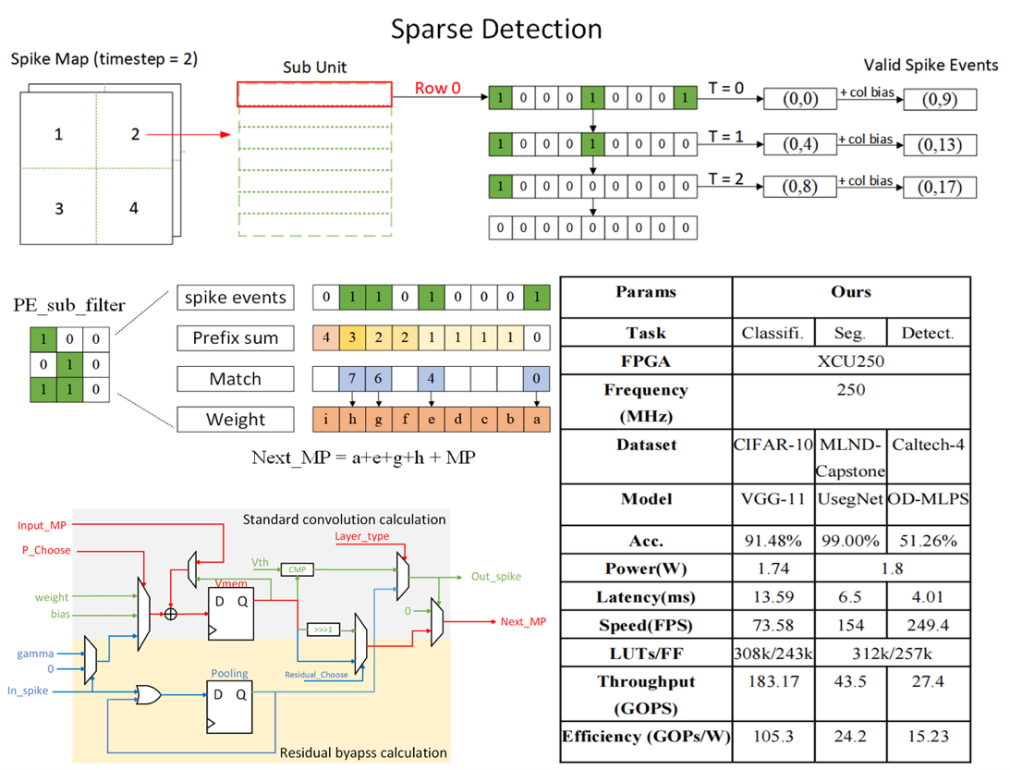
该架构创新性地从脉冲计算本质出发,在设计层面引入全局与局部分离的双层级稀疏脉冲检测机制,并配套轻量级稀疏响应单元,实现对脉冲信号在时间与空间维度上的冗余进行快速捕获与高效利用。同时,系统提出的可重构脉冲卷积数据流能够根据网络拓扑自适应切换稀疏检测策略,并动态调整脉冲神经元的脉冲触发与权重输入路径,以灵活支持多样化的卷积操作,涵盖标准、转置、空洞及残差卷积等多种结构形式,显著增强了系统的模型兼容性与结构适应能力。
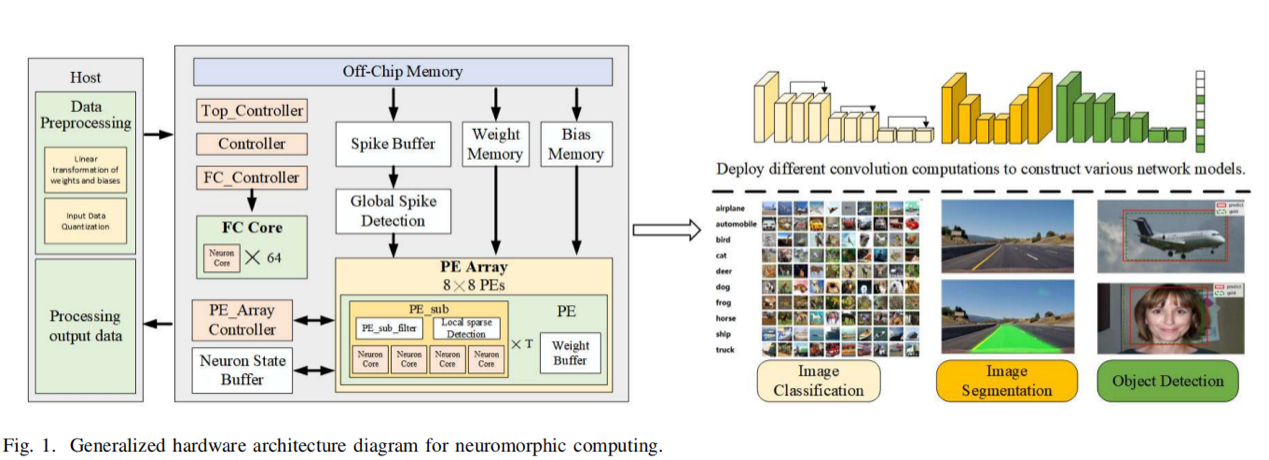
在基于现场可编程门阵列(FPGA)的硬件平台上,SConvNSys展现出优异的综合性能。在图像分类任务中,CIFAR-10与CIFAR-100数据集上的识别准确率分别达到91.48%与68.54%,系统功耗仅为1.8W,处理速度为73帧/秒;在图像分割任务中,以154帧/秒的速度实现了99.00%的分割准确率;在目标检测任务中,检测模型取得了74.20%的平均交并比(mIoU),卷积计算量为0.11十亿次运算(GOP),对应计算吞吐率达27.4 GOPS,能效高达15.23 GOPS/W。该架构在能效与性能方面表现突出,可广泛应用于低功耗智能视觉、边缘AI及嵌入式神经形态计算系统,为高效脉冲神经网络加速器的设计与实现提供了重要技术支撑。
该论文是团队近期在T-VLSI期刊上发表的第二项成果,由我院研究生梁应章、崔友锋与教师叶武剑、刘怡俊共同完成,并以广东工业大学集成电路学院为第一完成单位。
刘怡俊教授团队长期深耕脉冲计算架构与智能芯片加速技术,已累计发表SCI论文70余篇,其中多项成果发表于本领域国际高水平期刊,包括IEEE T-CAS-I (2篇)、T-CAS-II (1篇)、T-VLSI (2篇)、T-CAD (3篇)、Neural Networks (1篇) 及 Applied Intelligence (1篇)等。





