近日,集成电路学院熊晓明教授团队接连在人工智能芯片领域取得重要进展,在IEEE Transactions on Circuits and Systems II: Express Briefs(TCAS-II)、ACM Transactions on Embedded Computing Systems (TECS)、Electronics Letter (IET-EL)、IET Circuits, Devices and Systems (IET-CDS)等期刊上发表了一系列研究成果。TCAS-II是电路与系统领域顶级期刊,TECS是集成电路领域公认的最具影响力的刊物之一,也是中国计算机学会推荐的B类期刊(CCF-B),主要发表集成电路和嵌入式计算系统方向的最新研究成果。
在一系列研究成果中,论文[1]、[2]和[3]分别发表在TCAS-II、TECS和IET-EL上,胡湘宏博士为第一作者、熊晓明教授为通讯作者;论文[4] 和[5] 分别发表在IET-CDS 和IET-EL上,第一作者分别为博士生黄宏敏和硕士生李学铭,通讯作者为熊晓明教授和胡湘宏博士。
卷积神经网络(CNN)是一类包含卷积计算且具有深度结构的前馈神经网络,是深度学习的代表算法之一。CNN具有表征学习能力,能够按其阶层结构对输入信息进行平移不变分类,因此也被称为“平移不变人工神经网络”。当前,支持CNN网络推理和加速的硬件体系结构已成为人工智能芯片研究的热点之一。集成电路学院已发表的一系列最新研究成果聚焦第二代人工智能芯片(基于FPGA和ASIC芯片),加速AI应用的落地,促进人工智能与集成电路设计技术的发展融合,提高我国在人工智能领域的国际竞争力。
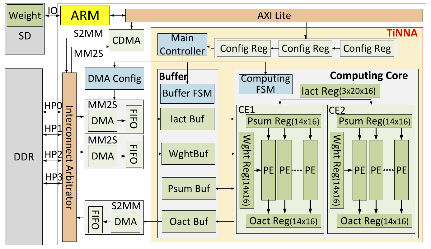
成果一:论文“TiNNA: A Tiny Accelerator for Neural Networks With Efficient DSP Optimization”发表在TCAS-II上[1]。
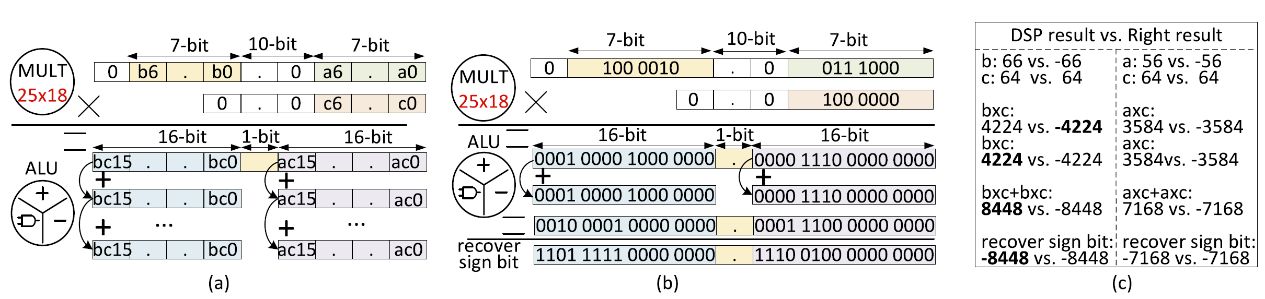
针对已有研究中DSP未能实现两个有符号INT-8乘法和导致其应用受到限制的问题,以及DSP只实现乘法导致需要额外LUT硬件来实现加法导致能量消耗大的问题,作者提出了DSP实现两个有符号INT-8乘法和加法的优化方法。基于该方法本文提出了一个轻量级神经网络加速器(TiNNA)。与在相同Xilinx ZC706 FPGA上最先进的AI加速器相比,TiNNA实现了1.7~7.3倍的DSP利用率。与其他基于FPGA的加速器相比,TiNNA实现了3.56倍的能源效率。

成果二:论文“High-Performance Reconfigurable DNN Accelerator on a Bandwidth-limited Embedded System”发表在TECS上[2]。
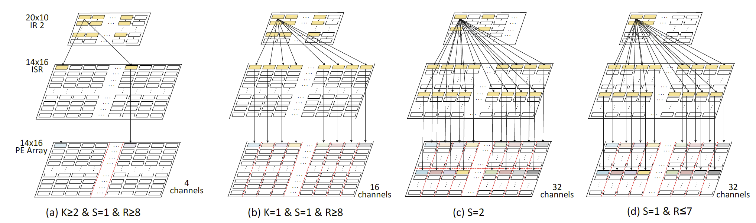
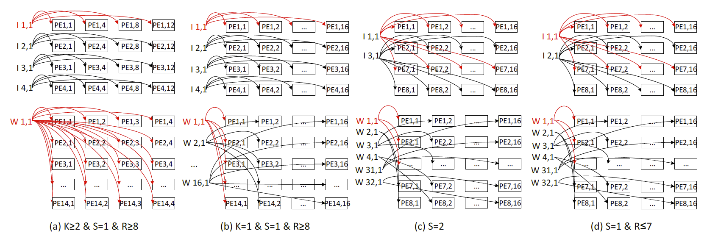
针对现实世界的机器视觉应用中,其他任务(如视频的采集和显示)占用大量带宽使得留给AI加速器的带宽少导致性能下降的问题,作者提出了一种宽带受限条件下的可重构轻量级神经网络加速器(ReTiNNA),并提出了一个高分辨率的实时目标检测系统。在2.23 GB/s的低带宽、90.261K LUTs和448个DSP的低硬件消耗下,ReTiNNA仍然可以在VGG16和ResNet50上实现155.86 GOPS和68.20 GOPS的高性能,比其他在FPGA上实现的最先进的设计更好。此外,实时目标检测系统可以实现19帧/秒的高分辨率目标检测速度。
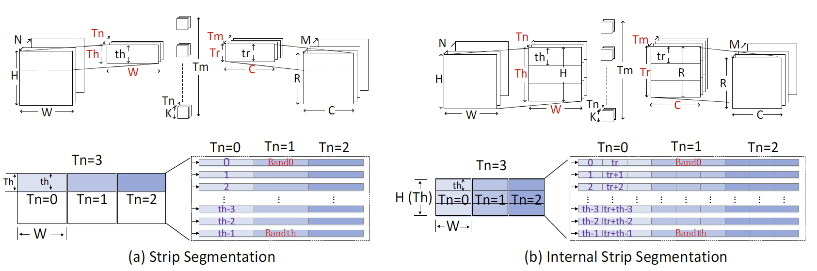
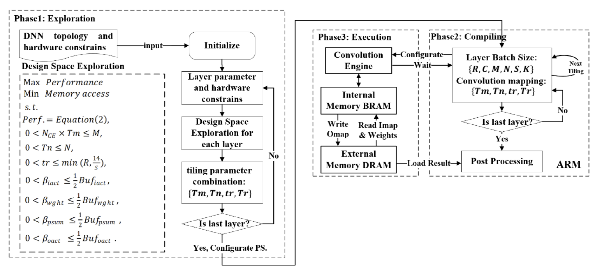

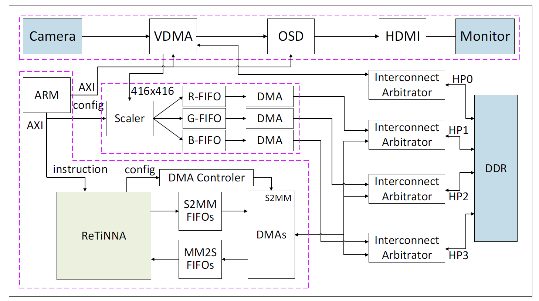
已发表的一系列研究成果:
[1]. X. Hu, X. Li, H. Huang, X. Zheng*, X. Xiong*, TiNNA: A Tiny Accelerator for Neural Networks With Efficient DSP Optimization, IEEE Transactions on Circuits and Systems II: Express Briefs, vol. 69, no. 4, pp. 2301-2305, April 2022, doi: 10.1109/TCSII.2022.3150980.
[2]. X. Hu, H. Huang, X. Li, X. Zheng*, Q. Ren, J. He, and X. Xiong*. High-Performance Reconfigurable DNN Accelerator on a Bandwidth-limited Embedded System. ACM Transactions on Embedded Computing Systems, doi: 10.1145/3530818.
[3]. X. Hu, T. Chen, H. Huang, Z. Liu, X. Li, X. Xiong*. Efficient Field-Programmable Gate Array-based Reconfigurable Accelerator for Deep Convolution Neural Network. Electronics Letter (IET journal), 2021, 57(6): 238-240, doi: 10.1049/ell2.12121.
[4]. H. Huang, X. Hu*, X. Li, X. Xiong*. An Efficient Loop Tiling Framework for Convolutional Neural Network Inference Accelerators. IET Circuits, Devices and Systems, 2022, 16(1): 116-123, doi: 10.1049/cds2.12091.
[5]. X. Li, H. Huang, Y. Liu, X. Hu*, X. Xiong*. A Digital Signal Processor-Efficient Accelerator for Depthwise Separable Convolution. Electronics Letter (IET journal), 2022, 58(7): 271-273, doi: 10.1049/ell2.12435.


